myPandoc Documentation
Convertisseur de documents inspiré du projet Pandoc
Qu'est-ce que myPandoc?
myPandoc est un convertisseur de documents inspiré du projet Pandoc original. Ce programme permet de convertir des documents entre différents formats (XML, JSON, Markdown) tout en préservant leur structure et leur contenu.

Fonctionnalités principales
Conversion multi-formats
Convertissez facilement entre XML, JSON et Markdown
Détection automatique
Détection automatique du format d'entrée
Bibliothèque custom
Bibliothèque de parsing personnalisée en Haskell
Structure préservée
Conservation de la structure du document pendant la conversion
Installation
Prérequis
- Stack (version 2.1.3 ou supérieure)
- GHC (installé automatiquement par Stack)
Compilation
makeCette commande va compiler le projet et générer l'exécutable mypandoc.
Utilisation
./mypandoc -i ifile -f oformat [-o ofile] [-e iformat]Options
-i ifile: Chemin vers le fichier d'entrée (obligatoire)-f oformat: Format de sortie (xml, json, markdown) (obligatoire)-o ofile: Chemin vers le fichier de sortie (optionnel, stdout par défaut)-e iformat: Format d'entrée (xml, json, markdown) (optionnel, détection automatique par défaut)
Exemples d'utilisation
./mypandoc -i example.xml -f markdown./mypandoc -i document.json -f xml -o result.xml./mypandoc -i document.txt -e json -f markdown -o result.mdFormats supportés
XML
XML (Extensible Markup Language) est un langage de balisage et un format de fichier pour stocker, transmettre et reconstruire des données arbitraires.
<document>
<header title="Simple example"></header>
<body>
<paragraph>This is a simple example</paragraph>
</body>
</document>JSON
JSON (JavaScript Object Notation) est un format léger d'échange de données qui est un sous-ensemble du langage JavaScript.
{
"header": {
"title": "Simple example"
},
"body": [
"This is a simple example"
]
}Markdown
Markdown est un langage de balisage léger pour créer du texte formaté à l'aide d'un éditeur de texte brut.
---
title: Simple example
---
This is a simple exampleArchitecture du projet
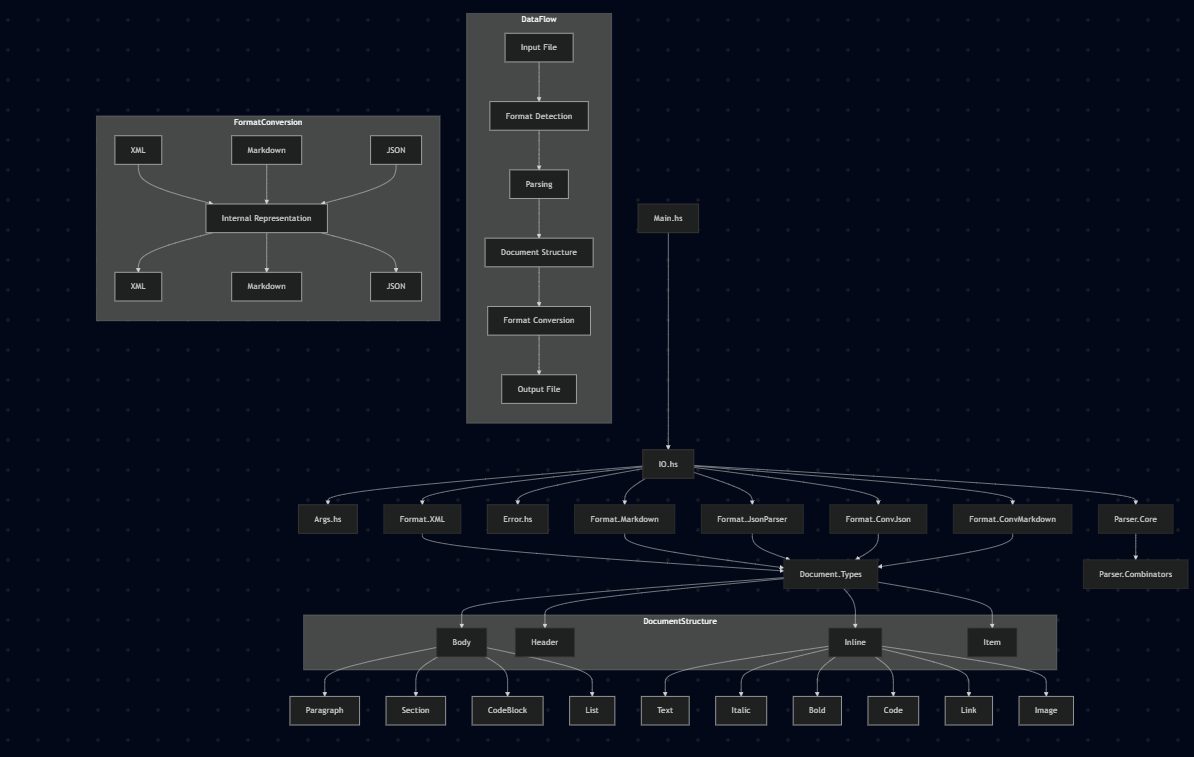
.
├── app/ # Code source de l'application principale
│ └── Main.hs # Point d'entrée du programme
├── src/ # Bibliothèques et modules
│ ├── Parser/ # Notre bibliothèque de parsing custom
│ │ ├── Combinators.hs # Combinateurs de parsers
│ │ ├── Core.hs # Fonctions de base pour le parsing
│ │ └── ...
│ ├── Document/ # Définition de la structure de document
│ │ ├── Types.hs # Types de données pour représenter un document
│ │ └── ...
│ ├── Format/ # Parsers et générateurs pour chaque format
│ │ ├── XML.hs # Parser et générateur XML
│ │ ├── JSON.hs # Parser et générateur JSON
│ │ ├── Markdown.hs # Parser et générateur Markdown
│ │ ├── ConvJson.hs # Converstiseur JSON
│ │ └── ...
├── test/ # Tests unitaires et tests d'intégration
├── examples/ # Exemples de documents dans différents formats
├── Makefile # Pour la compilation du projet
├── package.yaml # Configuration du package hpack
├── stack.yaml # Configuration de Stack
└── README.md # Ce fichierComposants clés
Bibliothèque de Parsing
Une bibliothèque de parsing personnalisée développée pour ce projet qui facilite l'implémentation des parsers pour chaque format.
Structure de Document
Une représentation intermédiaire commune qui permet de convertir facilement entre les différents formats.
Parsers de Format
Modules spécifiques pour analyser et générer chaque format supporté (XML, JSON, Markdown).
CLI
Interface en ligne de commande pour interagir avec le programme.
Bibliothèque de Parsing
Pour ce projet, nous avons développé notre propre bibliothèque de parsing en Haskell qui nous aide à implémenter les parsers pour les différents formats de fichiers.
Exemple de Combinateurs
-- Exemples de combinateurs de parsers
-- Ces fonctions permettent de combiner des parsers simples
-- pour créer des parsers plus complexes
-- Parser pour une chaîne spécifique
string :: String -> Parser String
string [] = return []
string (c:cs) = do
char c
string cs
return (c:cs)
-- Parser pour un choix entre deux parsers
(<|>) :: Parser a -> Parser a -> Parser a
p1 <|> p2 = Parser $ \input ->
case runParser p1 input of
Left _ -> runParser p2 input
right -> right
-- Parser qui applique une fonction à un résultat
(<$>) :: (a -> b) -> Parser a -> Parser b
f <$> p = Parser $ \input ->
case runParser p input of
Left err -> Left err
Right (rest, res) -> Right (rest, f res)Exemples
Exemple de conversion XML vers Markdown
Fichier d'entrée (example.xml)
<document>
<header title="Simple example" author="John Doe" date="2023-05-15"></header>
<body>
<paragraph>Ceci est un paragraphe d'exemple avec du texte <italic>en italique</italic> et <bold>en gras</bold>.</paragraph>
<section title="Une section">
<paragraph>Contenu de la section avec un <link href="https://example.com">lien</link>.</paragraph>
</section>
</body>
</document>Commande
./mypandoc -i example.xml -f markdown -o result.mdRésultat (result.md)
---
title: Simple example
author: John Doe
date: 2023-05-15
---
Ceci est un paragraphe d'exemple avec du texte *en italique* et **en gras**.
## Une section
Contenu de la section avec un [lien](https://example.com).Tests
Pour exécuter les tests unitaires et d'intégration:
make tests_runNotre suite de tests vérifie la bonne conversion entre les différents formats ainsi que le bon fonctionnement de la bibliothèque de parsing.
Fonctionnalités bonus
Support des tableaux
Support amélioré pour les tableaux en Markdown
Détection avancée
Détection avancée du format d'entrée
Gestion des erreurs
Gestion des erreurs détaillée et informative
Notes de bas de page
Support pour les notes de bas de page
Contributeurs
GBETCHEDJI James
@Noge
Salemgnk
@Scorpi7
KAKPO Emmanuelle
@emmanuellakakpo
Elias Hounnou
@saliehsab
Ce projet est réalisé dans le cadre du module B-FUN-400 à Epitech.